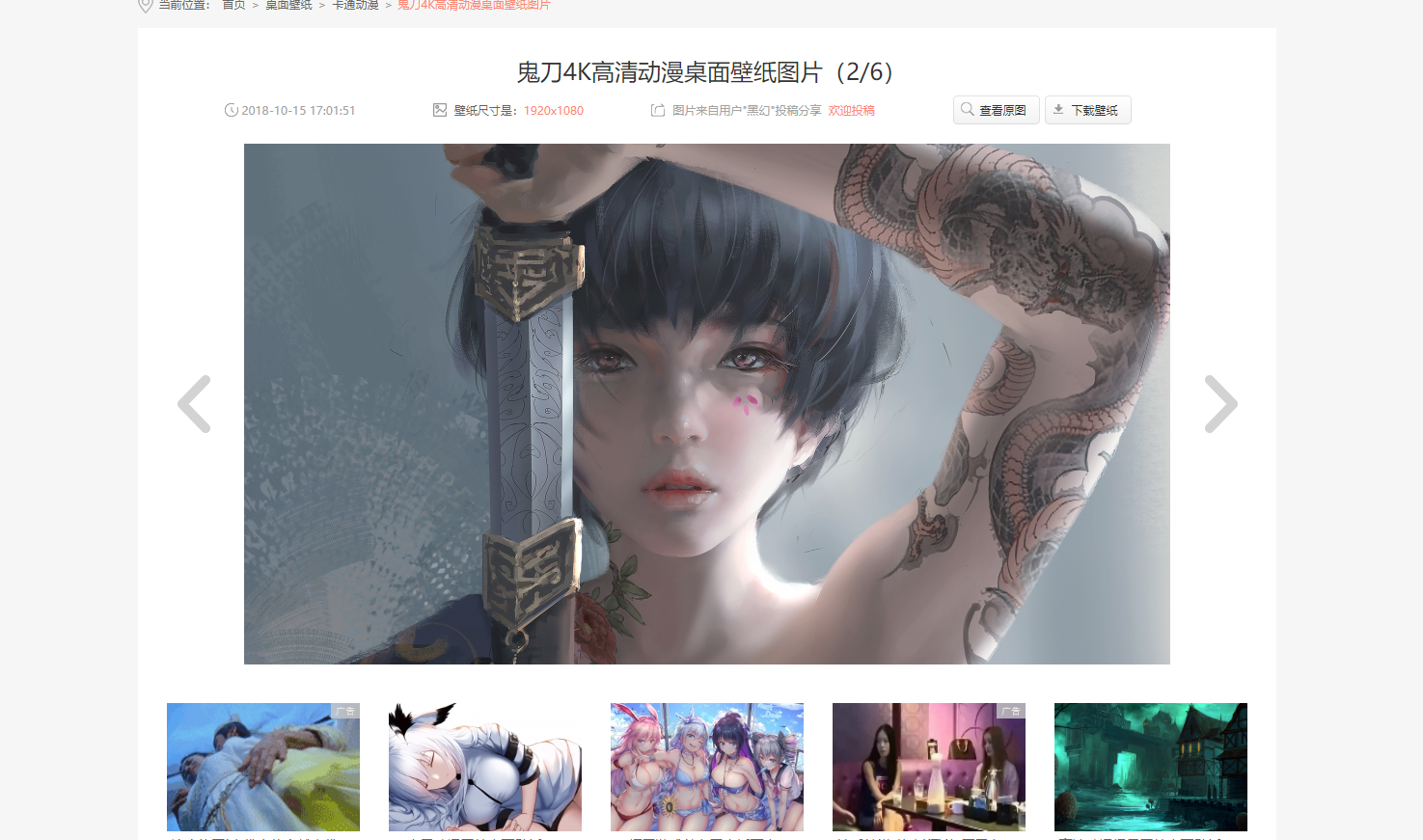
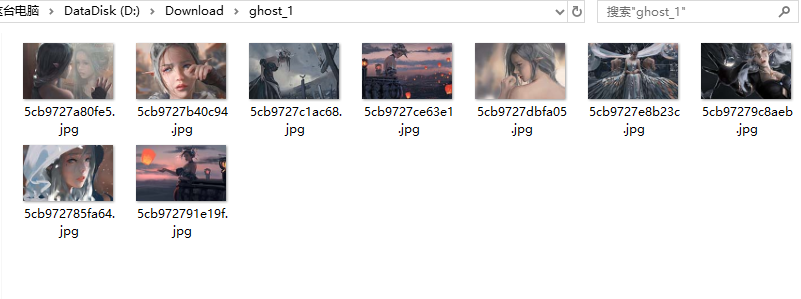
defmain(): htmlUrlList = getUrlList() for url in htmlUrlList: htmltext = getHtmlByUrl(url) getcontent(htmltext)
if __name__ == '__main__': while1: main() if a==0: a=0 if a==1: url = 'http://www.win4000.com/wallpaper_detail_169808.html' if a==2: url = 'http://www.win4000.com/wallpaper_detail_169594.html' if a==3: url = 'http://www.win4000.com/wallpaper_detail_169553.html' if a==4: url = 'http://www.win4000.com/wallpaper_detail_169629.html' if a==5: url = 'http://www.win4000.com/wallpaper_detail_169317.html' if a==6: url = 'http://www.win4000.com/wallpaper_detail_169116.html' if a==7: url = 'http://www.win4000.com/wallpaper_detail_169163.html' if a==8: url = 'http://www.win4000.com/wallpaper_detail_168984.html' if a==9: url = 'http://www.win4000.com/wallpaper_detail_168684.html' if a==10: url = 'http://www.win4000.com/wallpaper_detail_168524.html' a=a+1